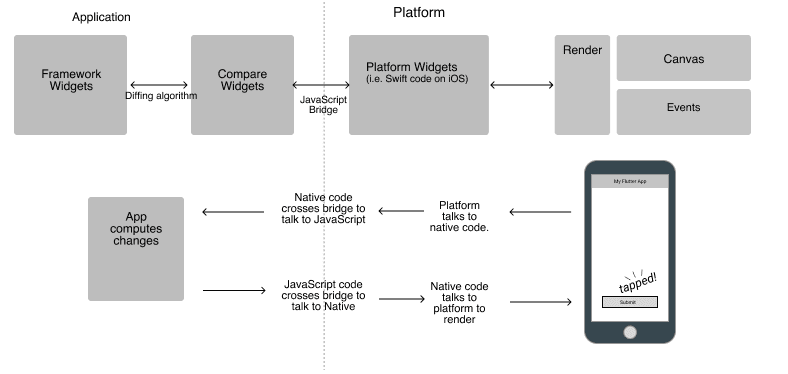
Android App Bundles(简称AAB)是一款全新动态化框架,与Instant App不同,AAB是借助Split Apk完成动态加载。
AAB与Instant Apps有何不同:Instant Apps是应用程序未下载,用户通过链接即可体验其部分功能,Instant Apps应用程序是运行在google play service上,而AAB插件是运行在应用程序进程内。AAB强调的是减少app包体积同时提供一样的用户功能体验,提供按需下载安装模式。
好处:
- Size更小【个人理解是相对用户来感知来说更小】
- 安装更快【base.apk被优化相对来说安装会更快】
- 支持动态发布
限制
- 仅限于通过 Google Play 发布的应用,(Google进一步巩固自身生态)
- 需要加入到 Google 的 beta program
- 最低支持版本Android 5.0 (API level 21),低于Android 5.0 (API level 21) 的版本GooglePlay会优化Size,但不支持动态交付。
原理
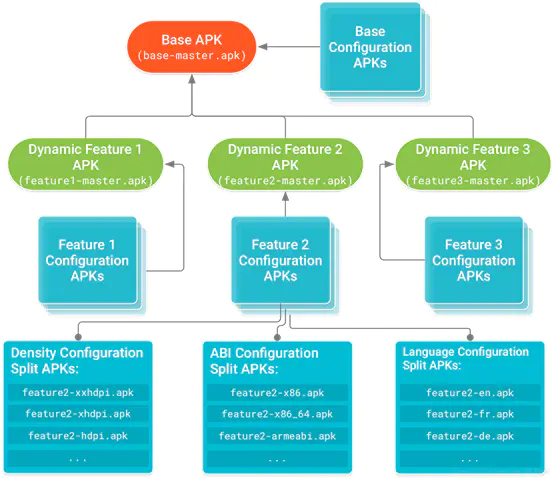
结合Google Play Dynamic Delivery (动态交付) , 实现动态功能。Android App Bundle 支持模块化,通过Dynamic Delivery with split APKs,将一个apk拆分成多个apk,按需加载(包括加载C/C++ libraries),这样开发者可以随时按需交付功能,而不是仅限在安装过程中。
- Base Apk 首次安装的apk,公共代码和资源,所以其他的模块都基于Base Apk
- Configuration APKs native libraries 和适配当前手机屏幕分辨率的资源
- Dynamic feature APKs 不需要在首次安装就加载的模块
下面介绍下SplitApk。
Split Apks
split apks是Android 5.0开始提供多apk构建机制,借助split apks可以将一个apk基于ABI和屏幕密度两个维度拆分城多个apk,这样可以有效减少apk体积。当用户下载应用程序安装包时,只会包含对应平台的so和资源。因为需要google play支持,所以国内就没戏了。针对不同cpu架构问题,国内应用开发商大部分都会将so文件只放在armabi目录下,如此做虽然可以有效减少包体积,但可能带来性能问题。
安装应用程序时,首先安装base apk,然后安装split apks。为了解splite apks运作原理,我们还是结合源码做简要分析。因为splite apks是Android 5.0开始支持,所以我们以5.0版本开始分析。
在ApplicationInfo中,增加splites apk相关字段。1
2
3
4
5
6
7
8
9
10
11
12/**
* Full paths to zero or more split APKs that, when combined with the base
* APK defined in {@link #sourceDir}, form a complete application.
*/
public String[] splitSourceDirs;
/**
* Full path to the publicly available parts of {@link #splitSourceDirs},
* including resources and manifest. This may be different from
* {@link #splitSourceDirs} if an application is forward locked.
*/
public String[] splitPublicSourceDirs;
LoadeApk中有PathClassLoader和Resources创建过程。LoadedApk#mClassLoader是PathClassLoader实例引用,接着分析PathClassLoader创建过程。
1 | public ClassLoader getClassLoader() { |
在创建PathClassLoader时,dex文件路径包含base app和split apps路径。LoadedApk#mResources是Resources实例引用,其创建过程如下。
1 | public Resources getResources(ActivityThread mainThread) { |
该方法中,split apks资源路径(LoadedApk#mSplitResDirs)也会被增加至Resources中。
以上简要介绍split apks加载过程,包括code和resources加载。split apks并不支持动态加载split apk,即base apk 和split apks在app安装时,全部安装。但通过split apks工作原理,可以发现其是能够支持按需加载。
Play Core Library
Play Core Library是AAB提供的核心库,用于下载、安装dynamic feature模块。
主工程模块app,首先分析MainActivity.kt文件。在MainActivity.kt的onCreate方法中,增加如下逻辑:
1 | override fun onCreate(savedInstanceState: Bundle?) { |
打印结果如下:1
2
3
4
5
6
7
8D/DynamicFeatures: installed module : native
D/DynamicFeatures: installed module : java
D/DynamicFeatures: installed module : kotlin
D/DynamicFeatures: installed module : assets
D/DynamicFeatures: split dir : /data/app/com.google.android.samples.dynamicapps.ondemand-1/split_assets.apk
D/DynamicFeatures: split dir : /data/app/com.google.android.samples.dynamicapps.ondemand-1/split_java.apk
D/DynamicFeatures: split dir : /data/app/com.google.android.samples.dynamicapps.ondemand-1/split_kotlin.apk
D/DynamicFeatures: split dir : /data/app/com.google.android.samples.dynamicapps.ondemand-1/split_native.apk
从运行结果可知,split apks(即使是on-demand模块)在debug模式下,是紧接着base apk安装完成后安装。
SplitInstallManager类提供获取已安装模块方法。1
Set<String> getInstalledModules();
因为Play Core Library非对外暴露接口都是混淆过的,因此就不直接附源码分析。但通过追踪分析源码可知,获取已安装模块的核心过程是:1
2
3
4
5
6
7
8
9private final String[] a() {
try {
PackageInfo var1;
return (var1 = this.d.getPackageManager().getPackageInfo(this.e, 0)) != null ? var1.splitNames : null;
} catch (NameNotFoundException var2) {
a.c("App is not found in PackageManager", new Object[0]);
return null;
}
}
通过PackageInfo#splitNames字段获取。
在示例中,每当我们需要启动dynamic feature模块时,都要判断该模块是否安装。如果没有安装,则启动下载,Play Core Library提供了比较完善的下载状态回调,比如下载进度,下载失败原因等等。
通过粗略分析这些混淆源码可知,下载与安装on-demand模块均是通过ipc交由google play完成。
兼容性问题
OS版本不高于6.0
当app运行设备版本不高于6.0时,需要使用SplitCompat库才能立即访问下载模块代码和资源。AAB提供SplitCompatApplication类用于开启SplitCompat。1
2
3
4
5
6
7
8
9public class SplitCompatApplication extends Application {
public SplitCompatApplication() {
}
protected void attachBaseContext(Context var1) {
super.attachBaseContext(var1);
SplitCompat.install(this);
}
}
在Application#attachBaseContext(Context)中调用SplitCompat.install(Context)。在该方法中主要完成split apks代码(dex和so)和资源的安装。
因为代码都是混淆过的,因此只能大概知道SplitCompat做了哪些操作。在SplitCompat#a(boolean)方法调用了
com.google.android.play.core.splitcompat.b.b.a()方法,其中有对不同版本OS兼容性处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14public static a a() {
if (VERSION.SDK_INT == 21) {
//com.google.android.play.core.splitcompat.b.c
return new c();
} else if (VERSION.SDK_INT == 22) {
//com.google.android.play.core.splitcompat.b.f
return new f();
} else if (VERSION.SDK_INT == 23) {
//com.google.android.play.core.splitcompat.b.g
return new g();
} else {
throw new AssertionError();
}
}
分别查看com.google.android.play.core.splitcompat.b.c、com.google.android.play.core.splitcompat.b.f、com.google.android.play.core.splitcompat.b.g,得知其主要做so加载和dex加载(dex前插,与mutil-dex类似)。split apks资源加载在SplitCompat#a(boolean)方法有反射调用AssetManager#addAssetPath(String)。
OS版本不低于8.0
在Android 8.0中,Instant Apps相关代码嵌入至Framework。因此如果on-demand模块用于Instant Apps中,需要在on-demand下载成功中,调用SplitInstallHelper.updateAppInfo(Context)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public static void updateAppInfo(Context var0) {
if (VERSION.SDK_INT > 25) {
a.a("Calling dispatchPackageBroadcast!", new Object[0]);
try {
Class var1;
Method var2;
(var2 = (var1 = Class.forName("android.app.ActivityThread")).getMethod("currentActivityThread")).setAccessible(true);
Object var3 = var2.invoke((Object)null);
Field var4;
(var4 = var1.getDeclaredField("mAppThread")).setAccessible(true);
Object var5;
(var5 = var4.get(var3)).getClass().getMethod("dispatchPackageBroadcast", Integer.TYPE, String[].class).invoke(var5, 3, new String[]{var0.getPackageName()});
a.a("Calling dispatchPackageBroadcast", new Object[0]);
} catch (Exception var6) {
a.a(var6, "Update app info with dispatchPackageBroadcast failed!", new Object[0]);
}
}
}
从上述代码得知其反射调用ActivityThread#dispatchPackageBroadcast方法。最终是调用至LoadedApk#updateApplicationInfo。该方法做了如下事情
- 重新创建mClassLoader
- 重新创建mResources
- 更新applicationInfo(调用LoadedApk#setApplicationInfo完成)。
参考资料
https://zhuanlan.zhihu.com/p/36902641
https://www.jianshu.com/p/57cccc680bb6