Kotlin 是一种在 Java 虚拟机上运行的静态类型编程语言 ,由 JetBrains 开发。Kotlin可以编译成Java字节码,也可以编译成JavaScript,方便在没有JVM的设备上运行。
设计目标
创建一种兼容Java的语言
让它比Java更安全,能够静态检测常见的陷阱。如:引用空指针
让它比Java更简洁,通过支持variable type inference,higher-order functions (closures),extension functions,mixins and first-class delegation等实现。
Kotlin,类似 Xtend 一样,旨在提供一种更好的 Java 而非重建整个新平台。这两种语言都向下编译为字节码(虽然 Xtend 是首先转换成相应的 Java 代码,再让 Java 编译器完成繁重的工作),而且两者都引入了函数和扩展函数(在某个有限范围内静态地增加一个新方法到某个已有类型的能力)。Xtend 是基于 Eclipse 的,而 Kotlin 是基于 IntelliJ 的,两者都提供无界面构建。
内联函数inline
调用某个方法实际上将程序执行顺序转移到该方法所存放在内存中某个地址,将方法的程序内容执行完后,再返回到转去执行该方法前的地方。这种转移操作要求在转去前要保护现场并记忆执行的地址,转回后先要恢复现场,并按原来保存地址继续执行。也就是通常说的压栈和出栈。因此,函数调用要有一定的时间和空间方面的开销。那么对于那些函数体代码不是很大,又频繁调用的函数来说,这个时间和空间的消耗会很大。 因此对于这种内容较短却又反复使用的方法我们可以通过使用内联函数来提升运行效率。
java中final关键字只是告诉编译器,在编译的时候考虑性能的提升,可以将final函数视为内联函数。但最后编译器会怎么处理,编译器会分析将final函数处理为内联和不处理为内联的性能比较了。(和垃圾处理机制类似,程序员只有建议权而没有决定权)
inline 的工作原理就是将内联函数的函数体复制到调用处实现内联。
inline 修饰符影响函数本身和传给它的 lambda 表达式:所有这些都将内联到调用处。
内联可能导致生成的代码增加;不过如果我们使用得当(即避免内联过大函数),性能上会有所提升,尤其是在循环中的“超多态(megamorphic)”调用处。
reified: 普通函数(非内联函数),不能包含具体化类型参数;若一个类型没有运行时表示(run-time representation)(如非具体化类型参数(non-reified type parameter)或虚拟类型,比如“Nothing”)不能作为一个具体化类型参数的实参。
公有 API 内联函数体内不允许使用非公有声明。

在Kotlin中对Java中的一些的接口的回调做了一些优化,可以使用一个lambda函数来代替。可以简化写一些不必要的嵌套回调方法。但是需要注意:在lambda表达式,只支持单抽象方法模型,也就是说设计的接口里面只有一个抽象的方法,才符合lambda表达式的规则,多个回调方法不支持。
Let
@kotlin.internal.InlineOnly
public inline fun <T, R> T.let(block: (T) -> R): R = block(this)
let函数适用的场景
场景一: 最常用的场景就是使用let函数处理需要针对一个可null的对象统一做判空处理。
场景二: 然后就是需要去明确一个变量所处特定的作用域范围内可以使用
With
@kotlin.internal.InlineOnly
public inline fun <T, R> with(receiver: T, block: T.() -> R): R = receiver.block()
with函数的适用的场景
适用于调用同一个类的多个方法时,可以省去类名重复,直接调用类的方法即可,经常用于Android中RecyclerView中onBinderViewHolder中,数据model的属性映射到UI上
示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//java实现
@Override
public void onBindViewHolder(ViewHolder holder, int position) {
ArticleSnippet item = getItem(position);
if (item == null) {
return;
}
holder.tvNewsTitle.setText(StringUtils.trimToEmpty(item.titleEn));
holder.tvNewsSummary.setText(StringUtils.trimToEmpty(item.summary));
String gradeInfo = "难度:" + item.gradeInfo;
String wordCount = "单词数:" + item.length;
String reviewNum = "读后感:" + item.numReviews;
String extraInfo = gradeInfo + " | " + wordCount + " | " + reviewNum;
holder.tvExtraInfo.setText(extraInfo);
...
}
//kotlin实现
override fun onBindViewHolder(holder: ViewHolder, position: Int){
val item = getItem(position)?: return
with(item){
holder.tvNewsTitle.text = StringUtils.trimToEmpty(titleEn)
holder.tvNewsSummary.text = StringUtils.trimToEmpty(summary)
holder.tvExtraInf.text = "难度:$gradeInfo | 单词数:$length | 读后感: $numReviews"
...
}
}
Run
@kotlin.internal.InlineOnly
public inline fun <T, R> T.run(block: T.() -> R): R = block()
适用于let,with函数任何场景。因为run函数是let,with两个函数结合体,准确来说它弥补了let函数在函数体内必须使用it参数替代对象,在run函数中可以像with函数一样可以省略,直接访问实例的公有属性和方法,另一方面它弥补了with函数传入对象判空问题,在run函数中可以像let函数一样做判空处理
示例:1
2
3
4
5
6
7
8
9
10
11//借助上个例子kotlin代码,使用run函数后的优化
override fun onBindViewHolder(holder: ViewHolder, position: Int){
getItem(position)?.run{
holder.tvNewsTitle.text = StringUtils.trimToEmpty(titleEn)
holder.tvNewsSummary.text = StringUtils.trimToEmpty(summary)
holder.tvExtraInf = "难度:$gradeInfo | 单词数:$length | 读后感: $numReviews"
...
}
}
Apply
@kotlin.internal.InlineOnly
public inline funT.apply(block: T.() -> Unit): T { block(); return this }
从结构上来看apply函数和run函数很像,唯一不同点就是它们各自返回的值不一样,run函数是以闭包形式返回最后一行代码的值,而apply函数的返回的是传入对象的本身。apply一般用于一个对象实例初始化的时候,需要对对象中的属性进行赋值。或者动态inflate出一个XML的View的时候需要给View绑定数据也会用到,这种情景非常常见。特别是在我们开发中会有一些数据model向View model转化实例化的过程中需要用到。
示例:1
2
3
4
5
6
7
8mSheetDialogView = View.inflate(activity, R.layout.biz_exam_plan_layout_sheet_inner, null).apply{
course_comment_tv_label.paint.isFakeBoldText = true
course_comment_tv_score.paint.isFakeBoldText = true
course_comment_tv_cancel.paint.isFakeBoldText = true
course_comment_tv_confirm.paint.isFakeBoldText = true
course_comment_seek_bar.max = 10
course_comment_seek_bar.progress = 0
}
多层级判空示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17mSectionMetaData?.apply{
//mSectionMetaData不为空的时候操作mSectionMetaData
}?.questionnaire?.apply{
//questionnaire不为空的时候操作questionnaire
}?.section?.apply{
//section不为空的时候操作section
}?.sectionArticle?.apply{
//sectionArticle不为空的时候操作sectionArticle
}
Also
@kotlin.internal.InlineOnly
@SinceKotlin(“1.1”)
public inline funT.also(block: (T) -> Unit): T { block(this); return this }
适用于let函数的任何场景,also函数和let很像,只是唯一的不同点就是let函数最后的返回值是最后一行的返回值,而also函数的返回值是返回当前的这个对象。一般可用于多个扩展函数链式调用
协程Coroutine
协程就像非常轻量级的线程,是运行在单线程中的并发程序。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
线程是由系统调度的,线程切换或线程阻塞的开销都比较大(涉及到同步锁;涉及到线程阻塞状态和可运行状态之间的切换;涉及到线程的创建及上下文的切换)。而协程依赖于线程,但协程挂起时不需要阻塞线程,几乎是无代价的,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。因此,协程的开销远远小于线程的开销。
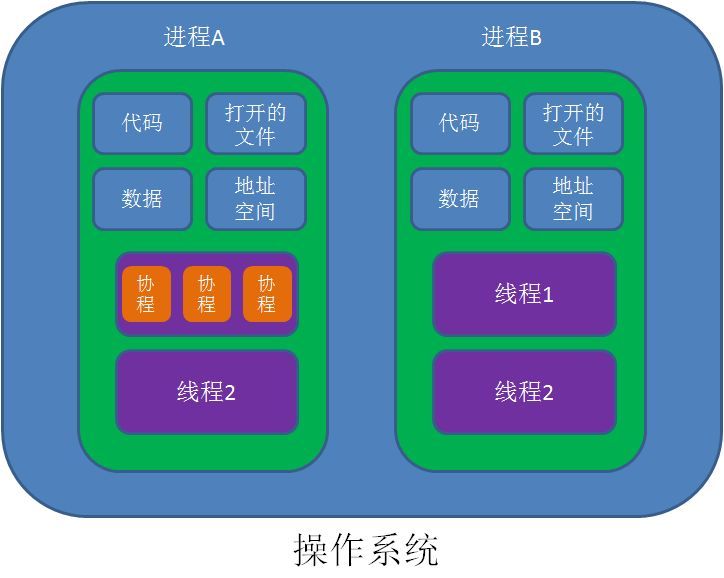
对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。协程能保留上一次调用时的状态,不需要像线程一样用回调函数,所以性能上会有提升。缺点是本质是个单线程,不能利用到单个CPU的多个核。
优势
因为在同一个线程里,协程之间的切换不涉及线程上下文的切换和线程状态的改变,不存在资源、数据并发,所以不用加锁,只需要判断状态就OK,所以执行效率比多线程高很多
协程是非阻塞式的(也有阻塞API),一个协程在进入阻塞后不会阻塞当前线程,当前线程会去执行其他协程任务
协程的切换,是通过yield API 让协程在空闲时(比如等待io,网络数据未到达)放弃执行权,然后在合适的时机再通过resume API 唤醒协程继续运行。协程一旦开始运行就不会结束,直到遇到yield交出执行权。Yield、resume 这一对 API 可以非常便捷的实现异步,这可是目前所有高级语法孜孜不倦追求的
suspend 关键字
协程天然亲近方法,协程表现为标记、切换方法、代码段,协程里使用 suspend 关键字修饰方法,既该方法可以被协程挂起,没用suspend修饰的方法不能参与协程任务,suspend修饰的方法只能在协程中只能与另一个suspend修饰的方法交流
一个协程内有多个 suspend 修饰的方法顺序书写时,代码也是顺序运行的,为什么,suspend 函数会将整个协程挂起,而不仅仅是这个 suspend 函数。1
2
3
4
5
6
7
8
9
10
11suspend fun requestToken(): Token { ... } // 挂起函数
suspend fun createPost(token: Token, item: Item): Post { ... } // 挂起函数
fun postItem(item: Item) {
GlobalScope.launch { // 创建一个新协程
val token = requestToken()
val post = createPost(token, item)
processPost(post)
// 需要异常处理,直接加上 try/catch 语句即可
}
}
创建协程
kotlin 中 GlobalScope 类提供了几个构造函数:
- launch - 创建协程
- async - 创建带返回值的协程,返回的是 Deferred 类
- withContext - 不创建新的协程,在指定协程上运行代码块
- runBlocking - 不是 GlobalScope 的 API,可以独立使用,区别是 runBlocking 里面的 delay 会阻塞线程,而 launch 创建的不会
kotlin 在 1.3 之后要求协程必须由 CoroutineScope 创建,CoroutineScope 不阻塞当前线程,在后台创建一个新协程,也可以指定协程调度器。CoroutineScope 并不运行协程,它只是确保您不会失去对协程的追踪。CoroutineScope 会跟踪所有协程,并且可以取消由它所启动的所有协程。比如 CoroutineScope.launch{} 可以看成 new Coroutine
launch
launch 函数定义:1
2
3
4
5
6
7
8public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
//调用
GlobalScope.launch(Dispatchers.Unconfined) {...}
我们需要关心的是 launch 的3个参数和返回值 Job:
1.CoroutineContext - 可以理解为协程的上下文,在这里我们可以设置 CoroutineDispatcher 协程运行的线程调度器,有 4种线程模式:
Dispatchers.Default - 使用共享的后台线程池
Dispatchers.IO - 用于IO操作的协程
Dispatchers.Main - 主线程
Dispatchers.Unconfined - 没指定,就是在当前线程(用于不消耗CPU时间的任务以及不更新UI的协程)
用newSingleThreadContext创建的调度器:为协和的运行启动了一个线程(一个专用的纯种是一种非常昂贵的资源)
不写的话就是 Dispatchers.Default 模式的,或者我们可以自己创建协程上下文,也就是线程池,newSingleThreadContext 单线程,newFixedThreadPoolContext 线程池,具体的可以点进去看看,这2个都是方法1
2val singleThreadContext = newSingleThreadContext("aa")
GlobalScope.launch(singleThreadContext) { ... }
2.CoroutineStart - 启动模式,默认是DEAFAULT,也就是创建就启动;还有一个是LAZY,意思是等你需要它的时候,再调用启动
DEAFAULT - 模式模式,不写就是默认
ATOMIC -
UNDISPATCHED
LAZY - 懒加载模式,你需要它的时候,再调用启动,看这个例子
1 | var job:Job = GlobalScope.launch( start = CoroutineStart.LAZY ){ |
3.block - 闭包方法体,定义协程内需要执行的操作
Job - 协程构建函数的返回值,可以把 Job 看成协程对象本身,协程的操作方法都在 Job 身上了
job.start() - 启动协程,除了 lazy 模式,协程都不需要手动启动
job.join() - 等待协程执行完毕
job.cancel() - 取消一个协程
job.cancelAndJoin() - 等待协程执行完毕然后再取消
async
async 同 launch 唯一的区别就是 async 是有返回值的,看下面的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21GlobalScope.launch(Dispatchers.Unconfined) {
val deferred = GlobalScope.async{
delay(1000L)
Log.d("AA","This is async ")
return@async "taonce"
}
Log.d("AA","协程 other start")
val result = deferred.await()
Log.d("AA","async result is $result")
Log.d("AA","协程 other end ")
}
Log.d("AA", "主线程位于协程之后的代码执行,时间: ${System.currentTimeMillis()}")
//运行结果
This is async
协程 other start
主线程位于协程之后的代码执行,时间: 1553866185250
async result is taonce
协程 other end
async 返回的是 Deferred 类型,Deferred 继承自 Job 接口,Job有的它都有,增加了一个方法 await ,这个方法接收的是 async 闭包中返回的值,async 的特点是不会阻塞当前线程,但会阻塞所在协程,也就是挂起。
但是注意啊,async 并不会阻塞线程,只是阻塞锁调用的协程
runBlocking
runBlocking 和 launch 区别的地方就是 runBlocking 的 delay 方法是可以阻塞当前的线程的,和Thread.sleep() 一样,看下面的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15fun main(args: Array<String>) {
runBlocking {
// 阻塞1s
delay(1000L)
println("This is a coroutines ${TimeUtil.getTimeDetail()}")
}
// 阻塞2s
Thread.sleep(2000L)
println("main end ${TimeUtil.getTimeDetail()}")
}
~~~~~~~~~~~~~~log~~~~~~~~~~~~~~~~
This is a coroutines 11:00:51
main end 11:00:53
runBlocking 通常的用法是用来桥接普通阻塞代码和挂起风格的非阻塞代码,在 runBlocking 闭包里面可以启动另外的协程,协程里面是可以嵌套启动别的协程的。
协程的挂起和恢复
1.协程执行时, 协程和协程,协程和线程内代码是顺序运行的
最简单的协程运行模式,不涉及挂起时,谁写在前面谁先运行,后面的等前面的协程运行完之后再运行。涉及到挂起时,前面的协程挂起了,那么线程不会空闲,而是继续运行下一个协程,而前面挂起的那个协程在挂起结速后不会马上运行,而是等待当前正在运行的协程运行完毕后再去执行
2.协程挂起时,就不会执行了,而是等待挂起完成且线程空闲时才能继续执行
一个协程内有多个 suspend 修饰的方法顺序书写时,代码也是顺序运行的,为什么,suspend 函数会将整个协程挂起,而不仅仅是这个 suspend 函数。
suspend 修饰的方法挂起的是协程本身,而非该方法,注意这点,看下面的代码体会下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29suspend fun getToken(): String {
delay(300)
Log.d("AA", "getToken 开始执行,时间: ${System.currentTimeMillis()}")
return "ask"
}
suspend fun getResponse(token: String): String {
delay(100)
Log.d("AA", "getResponse 开始执行,时间: ${System.currentTimeMillis()}")
return "response"
}
fun setText(response: String) {
Log.d("AA", "setText 执行,时间: ${System.currentTimeMillis()}")
}
// 运行代码
GlobalScope.launch(Dispatchers.Main) {
Log.d("AA", "协程 开始执行,时间: ${System.currentTimeMillis()}")
val token = getToken()
val response = getResponse(token)
setText(response)
}
//运行结果
协程 开始执行,时间: 1553848676780
getToken 开始执行,时间: 1553848676781
getResponse 开始执行,时间: 1553848677088
setText 执行,时间: 1553848677190
在 getToken 方法将协程挂起时,getResponse 函数永远不会运行,只有等 getToken 挂起结速将协程恢复时才会运行。
多协程间 suspend 函数运行:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16GlobalScope.launch(Dispatchers.Unconfined){
var token = GlobalScope.async(Dispatchers.Unconfined) {
return@async getToken()
}.await()
var response = GlobalScope.async(Dispatchers.Unconfined) {
return@async getResponse(token)
}.await()
setText(response)
}
//运行结果
getToken 开始执行,时间: 1553848676781
getResponse 开始执行,时间: 1553848677088
setText 执行,时间: 1553848677190
注意我外面要包裹一层 GlobalScope.launch,要不运行不了。这里我们搞了2个协程出来,但是我们在这里使用了await,这样就会阻塞外部协程,所以代码还是按顺序执行的。这样适用于多个同级 IO 操作的情况,这样写比 rxjava 要省事不少。
协程挂起后再恢复时在哪个线程运行:
哪个线程恢复的协程,协程就运行在哪个线程中。
注意协程内部,若是在前面有代码切换了线程,后面的代码若是没有指定线程,那么就是运行在这个切换到的线程上的。
我们最好给异步任务在外面套一个协程,这样我们可以挂起整个异步任务,然后给每段代码指定运行线程调度器,这样省的因为协程内部挂起恢复变更线程而带来的问题。
非 Dispatchers.Main 调度器的协程,会在协程挂起后把协程当做一个任务 DelayedResumeTask 放到默认线程池 DefaultExecutor 队列的最后,在延迟的时间到达才会执行恢复协程任务。虽然多个协程之间可能不是在同一个线程上运行的,但是协程内部的机制可以保证我们书写的协程是按照我们指定的顺序或者逻辑自行。
delay、yield 区别
delay 和 yield 方法是协程内部的操作,可以挂起协程,区别是 delay 是挂起协程并经过执行时间恢复协程,当线程空闲时就会运行协程;yield 是挂起协程,让协程放弃本次 cpu 执行机会让给别的协程,当线程空闲时再次运行协程。我们只要使用 kotlin 提供的协程上下文类型,线程池是有多个线程的,再次执行的机会很快就会有的。
除了 main 类型,协程在挂起后都会封装成任务放到协程默认线程池的任务队列里去,有延迟时间的在时间过后会放到队列里去,没有延迟时间的直接放到队列里去
协程的取消
我们在创建协程过后可以接受一个 Job 类型的返回值,我们操作 job 可以取消协程任务,job.cancel 就可以了。
协程的取消有些特质,因为协程内部可以在创建协程的,这样的协程组织关系可以称为父协程,子协程:
- 父协程手动调用 cancel() 或者异常结束,会立即取消它的所有子协程(而抛出CancellationException却会当作正常的协程结束不会取消其父协程)
- 父协程必须等待所有子协程完成(处于完成或者取消状态)才能完成
- 子协程抛出未捕获的异常时,默认情况下会取消其父协程
现在问题来了,在 Thread 中我们想关闭线程有时候也不是掉个方法就行的,需要我们自行在线程中判断线程是不是已经结束了。在协程中一样,cancel 方法只是修改了协程的状态,在协程自身的方法比如 realy,yield 等中会判断协程的状态从而结束协程,但是若是在协程我们没有用这几个方法怎么办,比如都是逻辑代码,这时就要我们自己手动判断了,使用 job.isActive ,isActive 是个标记,用来检查协程状态
原理
每一个挂起点和初始挂起点对应的 Continuation 都会转化为一种状态,协程恢复只是跳转到下一种状态中。挂起函数将执行过程分为多个 Continuation 片段,并且利用状态机的方式保证各个片段是顺序执行的。
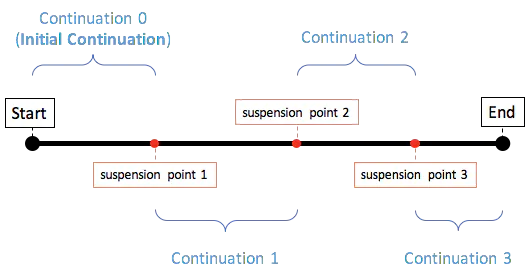
await()挂起函数恢复协程的原理是,将 launch 协程封装为 ResumeAwaitOnCompletion 作为 handler 节点添加到 aynsc 协程的 state.list,然后在 async 协程完成时会通知 handler 节点调用 launch 协程的 resume(result) 方法将结果传给 launch 协程,并恢复 launch 协程继续执行 await 挂起点之后的逻辑。
协程其实有三层包装。常用的launch和async返回的Job、Deferred,里面封装了协程状态,提供了取消协程接口,而它们的实例都是继承自AbstractCoroutine,它是协程的第一层包装。第二层包装是编译器生成的SuspendLambda的子类,封装了协程的真正运算逻辑,继承自BaseContinuationImpl,其中completion属性就是协程的第一层包装。第三层包装是线程调度时的DispatchedContinuation,封装了线程调度逻辑,包含了协程的第二层包装。三层包装都实现了Continuation接口,通过代理模式将协程的各层包装组合在一起,每层负责不同的功能。
下面是协程运行的流程图:
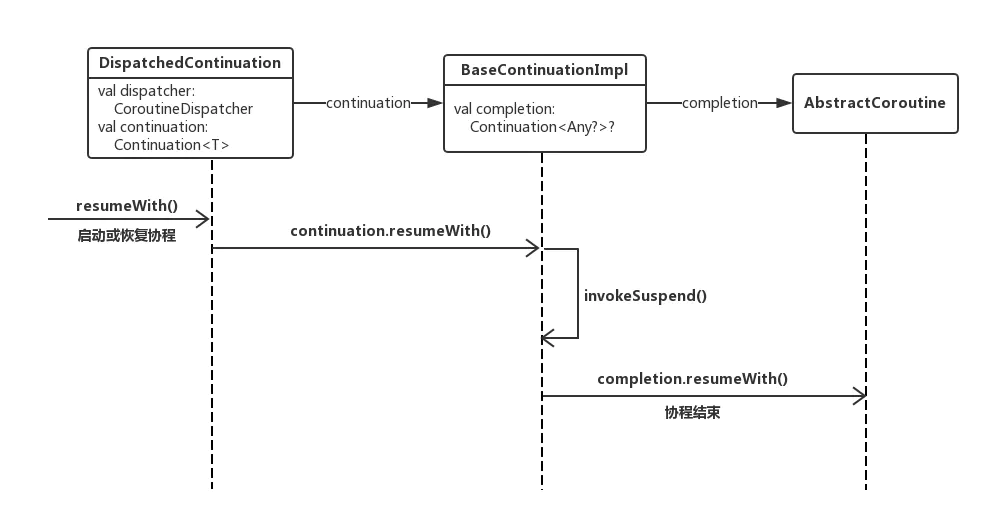
总结:协程就是一段可以挂起和恢复执行的运算逻辑,而协程的挂起是通过挂起函数实现的,挂起函数用状态机的方式用挂起点将协程的运算逻辑拆分为不同的片段,每次运行协程执行的不同的逻辑片段。所以协程有两个很大的好处:一是简化异步编程,支持异步返回;而是挂起不阻塞线程,提供线程利用率。
协程的并发
协程就是可以挂起和恢复执行的运算逻辑,挂起函数用状态机的方式用挂起点将协程的运算逻辑拆分为不同的片段,每次运行协程执行的不同的逻辑片段。所以协程在运行时只是线程中的一块代码,线程的并发处理方式都可以用在协程上。不过协程还提供两种特有的方式,一是不阻塞线程的互斥锁Mutex,一是通过 ThreadLocal 实现的协程局部数据。
Mutex 协程互斥锁
线程中锁都是阻塞式,在没有获取锁时无法执行其他逻辑,而协程可以通过挂起函数解决这个,没有获取锁就挂起协程,获取后再恢复协程,协程挂起时线程并没有阻塞可以执行其他逻辑。这种互斥锁就是 Mutex,它与 synchronized 关键字有些类似,还提供了 withLock 扩展函数,替代常用的 mutex.lock; try {…} finally { mutex.unlock() }1
2
3
4
5
6
7
8
9
10
11
12fun main(args: Array<String>) = runBlocking<Unit> {
val mutex = Mutex()
var counter = 0
repeat(10000) {
GlobalScope.launch {
mutex.withLock {
counter ++
}
}
}
println("The final count is $counter")
}
Mutex的使用比较简单,不过需要注意的是多个协程竞争的应该是同一个Mutex互斥锁。
ThreadLocal
线程中可以使用ThreadLocal作为线程局部数据,每个线程中的数据都是独立的。协程中可以通过ThreadLocal.asContextElement()扩展函数实现协程局部数据,每次协程切换会恢复之前的值。先看下面的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24fun main(args: Array<String>) = runBlocking<Unit> {
val threadLocal = ThreadLocal<String>().apply { set("Init") }
printlnValue(threadLocal)
val job = GlobalScope.launch(threadLocal.asContextElement("launch")) {
printlnValue(threadLocal)
threadLocal.set("launch changed")
printlnValue(threadLocal)
yield()
printlnValue(threadLocal)
}
job.join()
printlnValue(threadLocal)
}
private fun printlnValue(threadLocal: ThreadLocal<String>) {
println("${Thread.currentThread()} thread local value: ${threadLocal.get()}")
}
//输出如下:
Thread[main,5,main] thread local value: Init
Thread[DefaultDispatcher-worker-1,5,main] thread local value: launch
Thread[DefaultDispatcher-worker-1,5,main] thread local value: launch changed
Thread[DefaultDispatcher-worker-2,5,main] thread local value: launch
Thread[main,5,main] thread local value: Init
上面的输出有个疑问的地方,为什么执行yield()挂起函数后 threadLocal 的值不是launch changed而变回了launch?
最重要的牢记它的原理:启动和恢复时保存ThreadLocal在当前线程的值,并修改为 value,挂起和结束时修改当前线程ThreadLocal的值为之前保存的值。
委托by
委托模式是软件设计模式中的一项基本技巧。在委托模式中,有两个对象参与处理同一个请求,接受请求的对象将请求委托给另一个对象来处理。Kotlin 直接支持委托模式,更加优雅,简洁。Kotlin 通过关键字 by 实现委托。
类委托
类的委托即一个类中定义的方法实际是调用另一个类的对象的方法来实现的。
以下实例中派生类 Derived 继承了接口 Base 所有方法,并且委托一个传入的 Base 类的对象来执行这些方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 创建接口
interface Base {
fun print()
}
// 实现此接口的被委托的类
class BaseImpl(val x: Int) : Base {
override fun print() { print(x) }
}
// 通过关键字 by 建立委托类
class Derived(b: Base) : Base by b
fun main(args: Array<String>) {
val b = BaseImpl(10)
Derived(b).print() // 输出 10
}
在 Derived 声明中,by 子句表示,将 b 保存在 Derived 的对象实例内部,而且编译器将会生成继承自 Base 接口的所有方法, 并将调用转发给 b。
属性委托
属性委托指的是一个类的某个属性值不是在类中直接进行定义,而是将其托付给一个代理类,从而实现对该类的属性统一管理。
属性委托语法格式:
val/var <属性名>: <类型> by <表达式>
- var/val:属性类型(可变/只读)
- 属性名:属性名称
- 类型:属性的数据类型
- 表达式:委托代理类
by 关键字之后的表达式就是委托, 属性的 get() 方法(以及set() 方法)将被委托给这个对象的 getValue() 和 setValue() 方法。属性委托不必实现任何接口, 但必须提供 getValue() 函数(对于 var属性,还需要 setValue() 函数)。
该类需要包含 getValue() 方法和 setValue() 方法,且参数 thisRef 为进行委托的类的对象,prop 为进行委托的属性的对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import kotlin.reflect.KProperty
// 定义包含属性委托的类
class Example {
var p: String by Delegate()
}
// 委托的类
class Delegate {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String {
return "$thisRef, 这里委托了 ${property.name} 属性"
}
operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) {
println("$thisRef 的 ${property.name} 属性赋值为 $value")
}
}
fun main(args: Array<String>) {
val e = Example()
println(e.p) // 访问该属性,调用 getValue() 函数
e.p = "Runoob" // 调用 setValue() 函数
println(e.p)
}
输出结果为:
Example@433c675d, 这里委托了 p 属性
Example@433c675d 的 p 属性赋值为 Runoob
Example@433c675d, 这里委托了 p 属性
延迟属性 Lazy
lazy() 是一个函数, 接受一个 Lambda 表达式作为参数, 返回一个 Lazy 1
2
3
4
5
6
7
8
9
10
11
12
13
14val lazyValue: String by lazy {
println("computed!") // 第一次调用输出,第二次调用不执行
"Hello"
}
fun main(args: Array<String>) {
println(lazyValue) // 第一次执行,执行两次输出表达式
println(lazyValue) // 第二次执行,只输出返回值
}
执行输出结果:
computed!
Hello
Hello
你可以将局部变量声明为委托属性。 例如,你可以使一个局部变量惰性初始化:1
2
3
4
5
6
7fun example(computeFoo: () -> Foo) {
val memoizedFoo by lazy(computeFoo)
if (someCondition && memoizedFoo.isValid()) {
memoizedFoo.doSomething()
}
}
memoizedFoo 变量只会在第一次访问时计算。 如果 someCondition 失败,那么该变量根本不会计算。
提供委托provideDelegate
通过定义 provideDelegate 操作符,可以扩展创建属性实现所委托对象的逻辑。 如果 by 右侧所使用的对象将 provideDelegate 定义为成员或扩展函数,那么会调用该函数来 创建属性委托实例。
provideDelegate 的一个可能的使用场景是在创建属性时(而不仅在其 getter 或 setter 中)检查属性一致性。
例如,如果要在绑定之前检查属性名称,可以这样写:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class ResourceLoader<T>(id: ResourceID<T>) {
operator fun provideDelegate(
thisRef: MyUI,
prop: KProperty<*>
): ReadOnlyProperty<MyUI, T> {
checkProperty(thisRef, prop.name)
// 创建委托
}
private fun checkProperty(thisRef: MyUI, name: String) { …… }
}
fun <T> bindResource(id: ResourceID<T>): ResourceLoader<T> { …… }
class MyUI {
val image by bindResource(ResourceID.image_id)
val text by bindResource(ResourceID.text_id)
}
provideDelegate 的参数与 getValue 相同:
thisRef —— 必须与 属性所有者 类型(对于扩展属性——指被扩展的类型)相同或者是它的超类型
property —— 必须是类型 KProperty<*> 或其超类型。
在创建 MyUI 实例期间,为每个属性调用 provideDelegate 方法,并立即执行必要的验证。
如果没有这种拦截属性与其委托之间的绑定的能力,为了实现相同的功能, 你必须显式传递属性名,这不是很方便:1
2
3
4
5
6
7
8
9
10
11
12
13// 检查属性名称而不使用“provideDelegate”功能
class MyUI {
val image by bindResource(ResourceID.image_id, "image")
val text by bindResource(ResourceID.text_id, "text")
}
fun <T> MyUI.bindResource(
id: ResourceID<T>,
propertyName: String
): ReadOnlyProperty<MyUI, T> {
checkProperty(this, propertyName)
// 创建委托
}
在生成的代码中,会调用 provideDelegate 方法来初始化辅助的 prop$delegate 属性。 比较对于属性声明 val prop: Type by MyDelegate() 生成的代码与 上面(当 provideDelegate 方法不存在时)生成的代码:1
2
3
4
5
6
7
8
9
10
11
12class C {
var prop: Type by MyDelegate()
}
// 这段代码是当“provideDelegate”功能可用时
// 由编译器生成的代码:
class C {
// 调用“provideDelegate”来创建额外的“delegate”属性
private val prop$delegate = MyDelegate().provideDelegate(this, this::prop)
val prop: Type
get() = prop$delegate.getValue(this, this::prop)
}
请注意,provideDelegate 方法只影响辅助属性的创建,并不会影响为 getter 或 setter 生成的代码。
方法
Unit
在定义的时候忽略返回值等于是隐式声明函数的返回值是空。在Kotlin中,这种隐式返回的类型称之为:Unit。这个Unit类型的作用类似Java语言中的void类型。Unit是一种只有一个值——Unit的类型。这个值不需要显式返回。
闭包
Kotlin中的闭包是一个功能性自包含模块,可以在代码中被当做参数传递或者直接使用。函数里面声明函数,函数里面返回函数,就是闭包。
闭包就是一个代码块,用“{ }”包起来。Kotlin语言中有三种闭包形式:全局函数、自嵌套函数、匿名函数体。下面举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21fun main(args: Array<String>) {
// 执行test闭包的内容
test
}
// 定义一个比较测试闭包
val test = if (5 > 3) {
println("yes")
} else {
println("no")
}
// 原语句等价于 val test = println("yes") ,test是一个Unit对象,而Unit是个object,也就是个单例类,所以,上面的代码等价于
val test = Unit
object Unit {
init {
println("yes")
}
}
//因为单例对象只会初始化一次,所以不管定义多少次只会打印一次yes。
//实际上,val test = {println("yes")} ,大括号包裹的是另外一种,等价于 val test = fun(){ println("yes") } 这种才是函数的调用形式,使用test()
闭包的用途:能够读取其他函数的内部变量,另一个用处就是让这些变量的值始终保持在内存中(在内存中维持一个变量)。
注意:闭包会使得函数中的变量都被保存在内存中,内存消耗很大.闭包赋值给变量后,待变量销毁,内存释放
广义上来说,在Kotlin语言之中,函数、条件语句、控制流语句、花括号逻辑块、Lambda表达式都可以称之为闭包,但通常情况下,我们所指的闭包都是在说Lambda表达式。
双冒号 ::
Kotlin 中 双冒号操作符 表示把一个方法当做一个参数,传递到另一个方法中进行使用,通俗的来讲就是引用一个方法。
一般情况,我们调用当前类的方法 this 都是可省略的。为了防止作用域混淆 ,:: 调用的函数如果是类的成员函数或者是扩展函数,必须使用限定符,比如this。
参数默认值
1 | /** |
可变个数参数(vararg)
声明可变个数形参需要用到vararg关键字,当参数传递进入函数体之后,参数在函数体内可以通过集合的形式访问。函数最多可以有一个可变个数的形参,而且它必须出现在参数列表的最后。如:1
2
3
4
5
6
7
8
9
10
11
12
13/**
* 求多个数字的和
*/
fun sumNumbers(vararg numbers : Double) : Double{
var result : Double = 0.0
for (number in numbers) {
result += number
}
return result
}
// 使用的时候,则可以传任意多个参数
sumNumbers(1.2,2.56,3.14)
嵌套函数
在结构化编程盛行的年代,嵌套函数被广泛使用,在一个函数体中定义另外一个函数体就为嵌套函数。嵌套函数默认对外界是隐藏的,但仍然可以通过它们包裹的函数调用和使用它,举个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/**
* 嵌套函数demo
*
* 比较数字numberA和数字numberB的二次幂谁大
*/
fun compare(numberA: Int, numberB: Int) : Int{
var powerB = 0
// 嵌套函数,求一个数字的二次幂
fun power(num : Int) : Int{
return num * num
}
powerB = power(numberB)
if (numberA > powerB) {
return numberA
} else {
return powerB
}
}
fun main(args: Array<String>) {
// 报错!!!
// 无法直接调用内部嵌套的函数
power()
}
参考资料
https://blog.csdn.net/Zachary_46/article/details/80446851
https://www.runoob.com/kotlin/kotlin-delegated.html
Coroutine 协程
Kotlin Coroutines(协程) 完全解析(三)