Flow 有点类似 RxJava 的 Observable。因为 Observable 也有 Cold 、Hot 之分。
使用
Flow 能够返回多个异步计算的值,例如下面的 flow builder :1
2
3
4
5
6
7
8flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.collect{
println(it)
}
其中 Flow 接口,只有一个 collect 函数1
2
3
4public interface Flow<out T> {
@InternalCoroutinesApi
public suspend fun collect(collector: FlowCollector<T>)
}
如果熟悉 RxJava 的话,则可以理解为 collect() 对应subscribe(),而 emit() 对应onNext()。
创建
除了刚刚展示的 flow builder 可以用于创建 flow,还有其他的几种方式:
flowOf()1
2
3
4
5
6
7flowOf(1,2,3,4,5)
.onEach {
delay(100)
}
.collect{
println(it)
}
asFlow()1
2
3
4
5
6listOf(1, 2, 3, 4, 5).asFlow()
.onEach {
delay(100)
}.collect {
println(it)
}
channelFlow()1
2
3
4
5
6
7
8channelFlow {
for (i in 1..5) {
delay(100)
send(i)
}
}.collect{
println(it)
}
最后的 channelFlow builder 跟 flow builder 是有一定差异的。
flow 是 Cold Stream。在没有切换线程的情况下,生产者和消费者是同步非阻塞的。
channel 是 Hot Stream。而 channelFlow 实现了生产者和消费者异步非阻塞模型。
看下面的示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54//使用 flow builder 的情况,大致花费1秒
fun main() = runBlocking {
val time = measureTimeMillis {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.collect{
delay(100)
println(it)
}
}
print("cost $time")
}
//使用 channelFlow builder 的情况,大致花费700毫秒:
fun main() = runBlocking {
val time = measureTimeMillis{
channelFlow {
for (i in 1..5) {
delay(100)
send(i)
}
}.collect{
delay(100)
println(it)
}
}
print("cost $time")
}
//当然,flow 如果切换线程的话,花费的时间也是大致700毫秒,跟使用 channelFlow builder 效果差不多。
fun main() = runBlocking {
val time = measureTimeMillis{
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.flowOn(Dispatchers.IO)
.collect {
delay(100)
println(it)
}
}
print("cost $time")
}
切换线程
相比于 RxJava 需要使用 observeOn、subscribeOn 来切换线程,flow 会更加简单。只需使用 flowOn,下面的例子中,展示了 flow builder 和 map 操作符都会受到 flowOn 的影响。1
2
3
4
5
6
7
8
9
10
11flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.map {
it * it
}.flowOn(Dispatchers.IO)
.collect {
println(it)
}
而 collect() 指定哪个线程,则需要看整个 flow 处于哪个 CoroutineScope 下。
值得注意的地方,不要使用 withContext() 来切换 flow 的线程。
flow 取消
如果 flow 是在一个挂起函数内被挂起了,那么 flow 是可以被取消的,否则不能取消。
Terminal flow operators
Flow 的 API 有点类似于 Java Stream 的 API。它也同样拥有 Intermediate Operations、Terminal Operations。
Flow 的 Terminal 运算符可以是 suspend 函数,如 collect、single、reduce、toList 等;也可以是 launchIn 运算符,用于在指定 CoroutineScope 内使用 flow。1
2
3
4@ExperimentalCoroutinesApi // tentatively stable in 1.3.0
public fun <T> Flow<T>.launchIn(scope: CoroutineScope): Job = scope.launch {
collect() // tail-call
}
整理一下 Flow 的 Terminal 运算符
- collect
- single/first
- toList/toSet/toCollection
- count
- fold/reduce
- launchIn/produceIn/broadcastIn
Flow VS Sequences
每一个 Flow 其内部是按照顺序执行的,这一点跟 Sequences 很类似。
Flow 跟 Sequences 之间的区别是 Flow 不会阻塞主线程的运行,而 Sequences 会阻塞主线程的运行。
Flow VS RxJava
Kotlin 协程库的设计本身也参考了 RxJava ,下图展示了如何从 RxJava 迁移到 Kotlin 协程。(火和冰形象地表示了 Hot、Cold Stream)
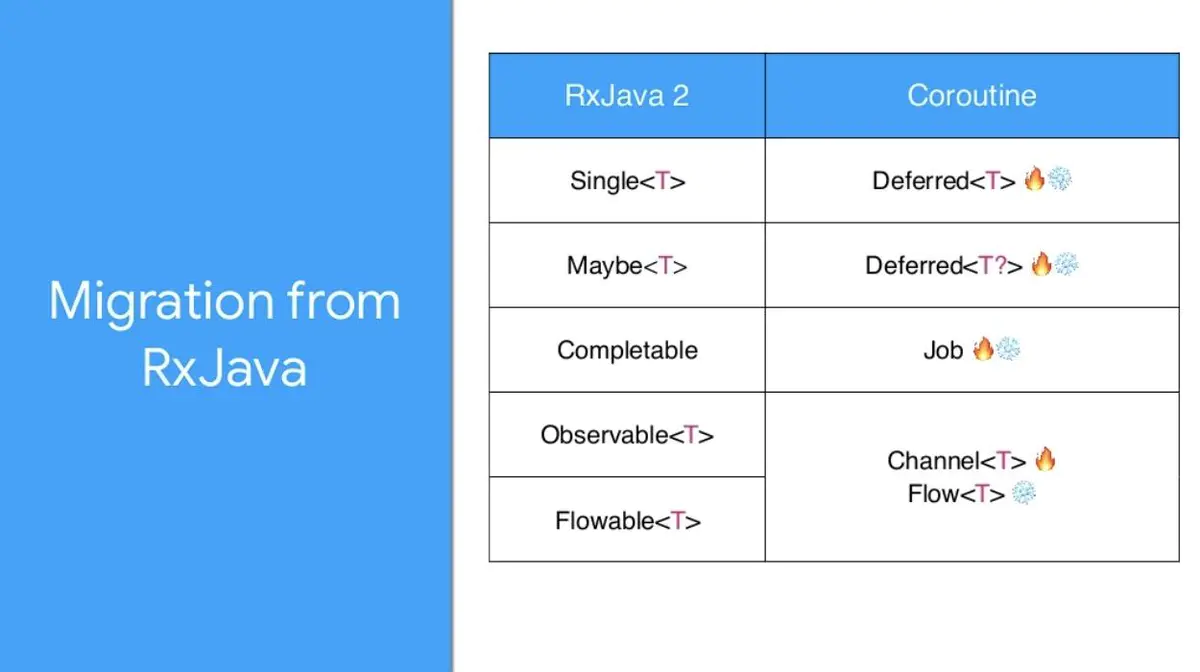
Cold Stream
flow 的代码块只有调用 collect() 才开始运行,正如 RxJava 创建的 Observables 只有调用 subscribe() 才开始运行一样。
Hot Stream
如图上所示,可以借助 Kotlin Channel 来实现 Hot Stream。
Completion
Flow 完成时(正常或出现异常时),如果需要执行一个操作,它可以通过两种方式完成:imperative、declarative。
1.imperative
通过使用 try … finally 实现1
2
3
4
5
6
7
8
9
10
11
12fun main() = runBlocking {
try {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.collect { println(it) }
} finally {
println("Done")
}
}
2.declarative
通过 onCompletion() 函数实现1
2
3
4
5
6
7
8
9fun main() = runBlocking {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.onCompletion { println("Done") }
.collect { println(it) }
}
3.onCompleted (借助扩展函数实现)
借助扩展函数可以实现类似 RxJava 的 onCompleted() 功能,只有在正常结束时才会被调用:1
2
3
4
5
6fun <T> Flow<T>.onCompleted(action: () -> Unit) = flow {
collect { value -> emit(value) }
action()
}
它的使用类似于 onCompletion()1
2
3
4
5
6
7
8
9fun main() = runBlocking {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.onCompleted { println("Completed...") }
.collect{println(it)}
}
但是假如 Flow 异常结束时,是不会执行 onCompleted() 函数的。
Backpressure
Backpressure 是响应式编程的功能之一。RxJava2 Flowable 支持的 Backpressure 策略,包括:
- MISSING:创建的 Flowable 没有指定背压策略,不会对通过 OnNext 发射的数据做缓存或丢弃处理。
- ERROR:如果放入 Flowable 的异步缓存池中的数据超限了,则会抛出 MissingBackpressureException 异常。
- BUFFER:Flowable 的异步缓存池同 Observable 的一样,没有固定大小,可以无限制添加数据,不会抛出 MissingBackpressureException 异常,但会导致 OOM。
- DROP:如果 Flowable 的异步缓存池满了,会丢掉将要放入缓存池中的数据。
- LATEST:如果缓存池满了,会丢掉将要放入缓存池中的数据。这一点跟 DROP 策略一样,不同的是,不管缓存池的状态如何,LATEST 策略会将最后一条数据强行放入缓存池中。
而 Flow 的 Backpressure 是通过 suspend 函数实现。
buffer() 对应 BUFFER 策略,conflate() 对应 LATEST 策略。示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77fun currTime() = System.currentTimeMillis()
var start: Long = 0
fun main() = runBlocking {
val time = measureTimeMillis {
(1..5)
.asFlow()
.onStart { start = currTime() }
.onEach {
delay(100)
println("Emit $it (${currTime() - start}ms) ")
}
.buffer()
.collect {
println("Collect $it starts (${currTime() - start}ms) ")
delay(500)
println("Collect $it ends (${currTime() - start}ms) ")
}
}
println("Cost $time ms")
}
执行结果:
Emit 1 (104ms)
Collect 1 starts (108ms)
Emit 2 (207ms)
Emit 3 (309ms)
Emit 4 (411ms)
Emit 5 (513ms)
Collect 1 ends (613ms)
Collect 2 starts (613ms)
Collect 2 ends (1114ms)
Collect 3 starts (1114ms)
Collect 3 ends (1615ms)
Collect 4 starts (1615ms)
Collect 4 ends (2118ms)
Collect 5 starts (2118ms)
Collect 5 ends (2622ms)
Collected in 2689 ms
---------------------------------------------------------------------------
fun main() = runBlocking {
val time = measureTimeMillis {
(1..5)
.asFlow()
.onStart { start = currTime() }
.onEach {
delay(100)
println("Emit $it (${currTime() - start}ms) ")
}
.conflate()
.collect {
println("Collect $it starts (${currTime() - start}ms) ")
delay(500)
println("Collect $it ends (${currTime() - start}ms) ")
}
}
println("Cost $time ms")
}
执行结果:
Emit 1 (106ms)
Collect 1 starts (110ms)
Emit 2 (213ms)
Emit 3 (314ms)
Emit 4 (419ms)
Emit 5 (520ms)
Collect 1 ends (613ms)
Collect 5 starts (613ms)
Collect 5 ends (1113ms)
Cost 1162 ms
DROP 策略
RxJava 的 contributor:David Karnok, 他写了一个kotlin-flow-extensions库,其中包括:FlowOnBackpressureDrop.kt,这个类支持 DROP 策略。1
2
3
4
5/**
* Drops items from the upstream when the downstream is not ready to receive them.
*/
@FlowPreview
fun <T> Flow<T>.onBackpressurureDrop() : Flow<T> = FlowOnBackpressureDrop(this)
使用这个库的话,可以通过使用 Flow 的扩展函数 onBackpressurureDrop() 来支持 DROP 策略。
Flow 异常处理
Flow 可以使用传统的 try…catch 来捕获异常:1
2
3
4
5
6
7
8
9
10
11fun main() = runBlocking {
flow {
emit(1)
try {
throw RuntimeException()
} catch (e: Exception) {
e.stackTrace
}
}.onCompletion { println("Done") }
.collect { println(it) }
}
另外,也可以使用 catch 操作符来捕获异常。
catch 操作符
上面讲述过 onCompletion 操作符。但是 onCompletion 不能捕获异常,只能用于判断是否有异常。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17fun main() = runBlocking {
flow {
emit(1)
throw RuntimeException()
}.onCompletion { cause ->
if (cause != null)
println("Flow completed exceptionally")
else
println("Done")
}.collect { println(it) }
}
执行结果:
1
Flow completed exceptionally
Exception in thread "main" java.lang.RuntimeException
......
catch 操作符可以捕获来自上游的异常1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19fun main() = runBlocking {
flow {
emit(1)
throw RuntimeException()
}
.onCompletion { cause ->
if (cause != null)
println("Flow completed exceptionally")
else
println("Done")
}
.catch{ println("catch exception") }
.collect { println(it) }
}
执行结果:
1
Flow completed exceptionally
catch exception
上面的代码如果把 onCompletion、catch 交换一下位置,则 catch 操作符捕获到异常后,不会影响到下游。因此,onCompletion 操作符不再打印”Flow completed exceptionally”
catch 操作符用于实现异常透明化处理。例如在 catch 操作符内,可以使用 throw 再次抛出异常、可以使用 emit() 转换为发射值、可以用于打印或者其他业务逻辑的处理等等。
但是,catch 只是中间操作符不能捕获下游的异常,类似 collect 内的异常。对于下游的异常,可以多次使用 catch 操作符来解决。
对于 collect 内的异常,除了传统的 try…catch 之外,还可以借助 onEach 操作符。把业务逻辑放到 onEach 操作符内,在 onEach 之后是 catch 操作符,最后是 collect()。1
2
3
4
5
6
7
8
9
10fun main() = runBlocking<Unit> {
flow {
......
}
.onEach {
......
}
.catch { ... }
.collect()
}
retry、retryWhen 操作符
像 RxJava 一样,Flow 也有重试的操作符。
如果上游遇到了异常,并使用了 retry 操作符,则 retry 会让 Flow 最多重试 retries 指定的次数。1
2
3
4
5
6
7public fun <T> Flow<T>.retry(
retries: Long = Long.MAX_VALUE,
predicate: suspend (cause: Throwable) -> Boolean = { true }
): Flow<T> {
require(retries > 0) { "Expected positive amount of retries, but had $retries" }
return retryWhen { cause, attempt -> attempt < retries && predicate(cause) }
}
例如,下面打印了三次”Emitting 1”、”Emitting 2”,最后两次是通过 retry 操作符打印出来的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25fun main() = runBlocking {
(1..5).asFlow().onEach {
if (it == 3) throw RuntimeException("Error on $it")
}.retry(2) {
if (it is RuntimeException) {
return@retry true
}
false
}
.onEach { println("Emitting $it") }
.catch { it.printStackTrace() }
.collect()
}
执行结果:
Emitting 1
Emitting 2
Emitting 1
Emitting 2
Emitting 1
Emitting 2
java.lang.RuntimeException: Error on 3
......
retry 操作符最终调用的是 retryWhen 操作符。下面的代码跟刚才的执行结果一致:1
2
3
4
5
6
7
8
9
10
11
12fun main() = runBlocking {
(1..5).asFlow().onEach {
if (it == 3) throw RuntimeException("Error on $it")
}
.onEach { println("Emitting $it") }
.retryWhen { cause, attempt ->
attempt < 2
}
.catch { it.printStackTrace() }
.collect()
}
因为 retryWhen 操作符的参数是谓词,当谓词返回 true 时才会进行重试。谓词还接收一个 attempt 作为参数表示尝试的次数,该次数是从0开始的。
Flow Lifecycle
RxJava 的 do 操作符能够监听 Observables 的生命周期的各个阶段。
Flow 并没有多那么丰富的操作符来监听其生命周期的各个阶段,目前只有 onStart、onCompletion 来监听 Flow 的创建和结束。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18fun main() = runBlocking {
(1..5).asFlow().onEach {
if (it == 3) throw RuntimeException("Error on $it")
}
.onStart { println("Starting flow") }
.onEach { println("On each $it") }
.catch { println("Exception : ${it.message}") }
.onCompletion { println("Flow completed") }
.collect()
}
执行结果:
Starting flow
On each 1
On each 2
Flow completed
Exception : Error on 3
Flow 线程操作
Flow 只需使用 flowOn 操作符,而不必像 RxJava 需要去深入理解 observeOn、subscribeOn 之间的区别。
RxJava 的 observeOn 操作符,接收一个 Scheduler 参数,用来指定下游操作运行在特定的线程调度器 Scheduler 上。Flow 的 flowOn 操作符,接收一个 CoroutineContext 参数,影响的是上游的操作。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20val customerDispatcher = Executors.newFixedThreadPool(5).asCoroutineDispatcher()
fun main() = runBlocking {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}.map {
it * it
}.flowOn(Dispatchers.IO)
.map {
it+1
}
.flowOn(customerDispatcher)
.collect {
println("${Thread.currentThread().name}: $it")
}
}
flow builder 和两个 map 操作符都会受到两个flowOn的影响,其中 flow builder 和 map 操作符都会受到第一个flowOn的影响并使用 Dispatchers.io 线程池,第二个 map 操作符会切换到指定的 customerDispatcher 线程池。
buffer 实现并发操作
上面介绍了 buffer 操作符对应 RxJava Backpressure 中的 BUFFER 策略。
事实上 buffer 操作符也可以并发地执行任务,它是除了使用 flowOn 操作符之外的另一种方式,只是不能显示地指定 Dispatchers。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24fun main() = runBlocking {
val time = measureTimeMillis {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}
.buffer()
.collect { value ->
delay(300)
println(value)
}
}
println("Collected in $time ms")
}
执行结果:
1
2
3
4
5
Collected in 1676 ms
在上述例子中,所有的 delay 所花费的时间是2000ms。然而通过 buffer 操作符并发地执行 emit,再顺序地执行 collect 函数后,所花费的时间在 1700ms 左右。
flatMapMerge 实现并行操作
在讲解并行操作之前,先来了解一下并发和并行的区别。
- 并发(concurrency):是指一个处理器同时处理多个任务。
- 并行(parallelism):是多个处理器或者是多核的处理器同时处理多个不同的任务。并行是同时发生的多个并发事件,具有并发的含义,而并发则不一定是并行。
RxJava 可以借助 flatMap 操作符实现并行,亦可以使用 ParallelFlowable 类实现并行操作。Flow 也有相应的操作符 flatMapMerge 可以实现并行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16fun main() = runBlocking {
val result = arrayListOf<Int>()
for (index in 1..100){
result.add(index)
}
result.asFlow()
.flatMapMerge {
flow {
emit(it)
}
.flowOn(Dispatchers.IO)
}
.collect { println("$it") }
}
Flow 其他的操作符
transform
在使用 transform 操作符时,可以任意多次调用 emit ,这是 transform 跟 map 最大的区别:1
2
3
4
5
6
7
8
9
10fun main() = runBlocking {
(1..5).asFlow()
.transform {
emit(it * 2)
delay(100)
emit(it * 4)
}
.collect { println(it) }
}
transform 也可以使用 emit 发射任意值:1
2
3
4
5
6
7
8
9
10fun main() = runBlocking {
(1..5).asFlow()
.transform {
emit(it * 2)
delay(100)
emit("emit $it")
}
.collect { println(it) }
}
take
take 操作符只取前几个 emit 发射的值。1
2
3
4
5
6fun main() = runBlocking {
(1..5).asFlow()
.take(2)
.collect { println(it) }
}
reduce
类似于 Kotlin 集合中的 reduce 函数,能够对集合进行计算操作。
例如,对平方数列求和:1
2
3
4
5
6
7
8fun main() = runBlocking {
val sum = (1..5).asFlow()
.map { it * it }
.reduce { a, b -> a + b }
println(sum)
}
例如,计算阶乘:1
2
3
4
5
6fun main() = runBlocking {
val sum = (1..5).asFlow().reduce { a, b -> a * b }
println(sum)
}
fold
也类似于 Kotlin 集合中的 fold 函数,fold 也需要设置初始值。1
2
3
4
5
6
7
8fun main() = runBlocking {
val sum = (1..5).asFlow()
.map { it * it }
.fold(0) { a, b -> a + b }
println(sum)
}
在上述代码中,初始值为0就类似于使用 reduce 函数实现对平方数列求和。
而对于计算阶乘:1
2
3
4
5
6fun main() = runBlocking {
val sum = (1..5).asFlow().fold(1) { a, b -> a * b }
println(sum)
}
zip
zip 是可以将2个 flow 进行合并的操作符。1
2
3
4
5
6
7
8
9
10
11
12
13
14fun main() = runBlocking {
val flowA = (1..5).asFlow()
val flowB = flowOf("one", "two", "three","four","five")
flowA.zip(flowB) { a, b -> "$a and $b" }
.collect { println(it) }
}
执行结果:
1 and one
2 and two
3 and three
4 and four
5 and five
zip 操作符会把 flowA 中的一个 item 和 flowB 中对应的一个 item 进行合并。即使 flowB 中的每一个 item 都使用了 delay() 函数,在合并过程中也会等待 delay() 执行完后再进行合并。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20fun main() = runBlocking {
val flowA = (1..5).asFlow()
val flowB = flowOf("one", "two", "three", "four", "five").onEach { delay(100) }
val time = measureTimeMillis {
flowA.zip(flowB) { a, b -> "$a and $b" }
.collect { println(it) }
}
println("Cost $time ms")
}
执行结果:
1 and one
2 and two
3 and three
4 and four
5 and five
Cost 561 ms
如果 flowA 中 item 个数大于 flowB 中 item 个数,执行合并后新的 flow 的 item 个数 = 较小的 flow 的 item 个数。:1
2
3
4
5
6
7
8
9
10
11
12
13
14fun main() = runBlocking {
val flowA = (1..6).asFlow()
val flowB = flowOf("one", "two", "three","four","five")
flowA.zip(flowB) { a, b -> "$a and $b" }
.collect { println(it) }
}
执行结果:
1 and one
2 and two
3 and three
4 and four
5 and five
combine
combine 虽然也是合并,但是跟 zip 不太一样。
使用 combine 合并时,每次从 flowA 发出新的 item ,会将其与 flowB 的最新的 item 合并。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18fun main() = runBlocking {
val flowA = (1..5).asFlow().onEach { delay(100) }
val flowB = flowOf("one", "two", "three","four","five").onEach { delay(200) }
flowA.combine(flowB) { a, b -> "$a and $b" }
.collect { println(it) }
}
执行结果:
1 and one
2 and one
3 and one
3 and two
4 and two
5 and two
5 and three
5 and four
5 and five
flattenMerge
其实,flattenMerge 不会组合多个 flow ,而是将它们作为单个流执行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21fun main() = runBlocking {
val flowA = (1..5).asFlow()
val flowB = flowOf("one", "two", "three","four","five")
flowOf(flowA,flowB)
.flattenConcat()
.collect{ println(it) }
}
执行结果:
1
2
3
4
5
one
two
three
four
five
为了能更清楚地看到 flowA、flowB 作为单个流的执行,对他们稍作改动。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21fun main() = runBlocking {
val flowA = (1..5).asFlow().onEach { delay(100) }
val flowB = flowOf("one", "two", "three","four","five").onEach { delay(200) }
flowOf(flowA,flowB)
.flattenMerge(2)
.collect{ println(it) }
}
执行结果:
1
one
2
3
two
4
5
three
four
five
flatMapConcat
flatMapConcat 由 map、flattenConcat 操作符实现。1
2
3@FlowPreview
public fun <T, R> Flow<T>.flatMapConcat(transform: suspend (value: T) -> Flow<R>): Flow<R> =
map(transform).flattenConcat()
在调用 flatMapConcat 后,collect 函数在收集新值之前会等待 flatMapConcat 内部的 flow 完成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32fun currTime() = System.currentTimeMillis()
var start: Long = 0
fun main() = runBlocking {
(1..5).asFlow()
.onStart { start = currTime() }
.onEach { delay(100) }
.flatMapConcat {
flow {
emit("$it: First")
delay(500)
emit("$it: Second")
}
}
.collect {
println("$it at ${System.currentTimeMillis() - start} ms from start")
}
}
执行结果:
1: First at 114 ms from start
1: Second at 619 ms from start
2: First at 719 ms from start
2: Second at 1224 ms from start
3: First at 1330 ms from start
3: Second at 1830 ms from start
4: First at 1932 ms from start
4: Second at 2433 ms from start
5: First at 2538 ms from start
5: Second at 3041 ms from start
flatMapMerge
flatMapMerge 由 map、flattenMerge 操作符实现。1
2
3
4
5@FlowPreview
public fun <T, R> Flow<T>.flatMapMerge(
concurrency: Int = DEFAULT_CONCURRENCY,
transform: suspend (value: T) -> Flow<R>
): Flow<R> = map(transform).flattenMerge(concurrency)
flatMapMerge 是顺序调用内部代码块,并且并行地执行 collect 函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32fun currTime() = System.currentTimeMillis()
var start: Long = 0
fun main() = runBlocking {
(1..5).asFlow()
.onStart { start = currTime() }
.onEach { delay(100) }
.flatMapMerge {
flow {
emit("$it: First")
delay(500)
emit("$it: Second")
}
}
.collect {
println("$it at ${System.currentTimeMillis() - start} ms from start")
}
}
执行结果:
1: First at 116 ms from start
2: First at 216 ms from start
3: First at 319 ms from start
4: First at 422 ms from start
5: First at 525 ms from start
1: Second at 618 ms from start
2: Second at 719 ms from start
3: Second at 822 ms from start
4: Second at 924 ms from start
5: Second at 1030 ms from start
flatMapMerge 操作符有一个参数 concurrency ,它默认使用DEFAULT_CONCURRENCY,如果想更直观地了解 flatMapMerge 的并行,可以对这个参数进行修改。例如改成2,就会发现不一样的执行结果。
flatMapLatest
当发射了新值之后,上个 flow 就会被取消。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28fun currTime() = System.currentTimeMillis()
var start: Long = 0
fun main() = runBlocking {
(1..5).asFlow()
.onStart { start = currTime() }
.onEach { delay(100) }
.flatMapLatest {
flow {
emit("$it: First")
delay(500)
emit("$it: Second")
}
}
.collect {
println("$it at ${System.currentTimeMillis() - start} ms from start")
}
}
执行结果:
1: First at 114 ms from start
2: First at 220 ms from start
3: First at 321 ms from start
4: First at 422 ms from start
5: First at 524 ms from start
5: Second at 1024 ms from start
互操作性
Flow 仍然属于响应式范畴。开发者通过 kotlinx-coroutines-reactive 模块中 Flow.asPublisher() 和 Publisher.asFlow() ,可以方便地将 Flow 跟 Reactive Streams 进行互操作。