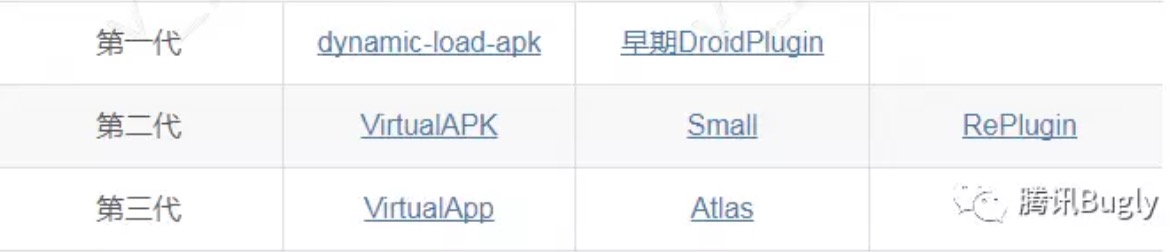
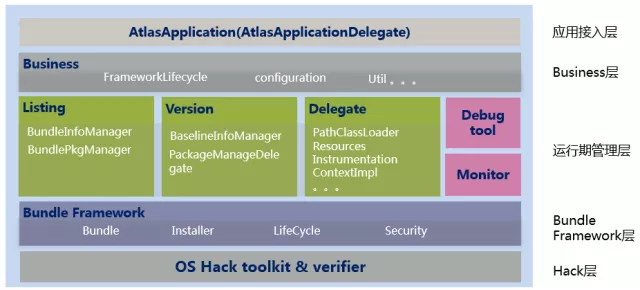
VirtualApp是一款运行于Android系统的沙盒产品,可以理解为轻量级的“Android虚拟机”。是一个开源的Android App虚拟化引擎,允许在其中创建虚拟空间,并在这个虚拟空间中运行其他应用。
本质
Android应用隔离是基于Linux系统的多用户机制实现的,即每个应用在安装时被分配了不同的Linux用户uid/gid。而在VirtualApp中,client应用(通过VirtualApp安装的应用)与host应用(即VirtualApp本身)是具有相同用户uid的。
因此,VirtualApp在运行时,包含以下三部分:
- Main Process,进程名io.virtualapp,主要负责VirtualApp用户界面及应用管理
- Server Process,进程名io.virtualapp:x,主要负责系统服务的代理,是通过Content Provider启动的
- VApp Process,进程名io.virtualapp:p[0-…],作为将来运行client应用的进程,当client应用启动后,其进程名会更新为client应用的包名
下面是在VirtualApp中运行应用后通过ps命令得到的结果:1
2
3
4generic_x86:/ $ ps |grep u0_a60
u0_a60 2385 1258 996260 54456 SyS_epoll_ 00000000 S io.virtualapp
u0_a60 2412 1258 980940 48272 SyS_epoll_ 00000000 S io.virtualapp:x
u0_a60 3705 1258 993632 54472 SyS_epoll_ 00000000 S org.galaxy.simpleapp
可以看到,以上进程,均是以VirtualApp的用户uid运行的。因此,Android应用隔离此时不再适用,我们可以对client应用进行hook而无需root权限。
注入逻辑
要想实现对一个APP的虚拟化,就是不直接把APP安装进系统,同时又要提供APP运行过程中所需的一切,从而可以让它误以为自己是运行在正常系统中。这里就需要实现系统服务的虚拟化和相关路径的虚拟化。
其中,系统服务的虚拟化主要靠注入大量framework组件来实现的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73@VirtualApp/lib/src/main/java/com/lody/virtual/client/core/InvocationStubManager.java
private void injectInternal() throws Throwable {
if (VirtualCore.get().isMainProcess()) {
return;
}
if (VirtualCore.get().isServerProcess()) {
addInjector(new ActivityManagerStub());
addInjector(new PackageManagerStub());
return;
}
if (VirtualCore.get().isVAppProcess()) {
addInjector(new LibCoreStub());
addInjector(new ActivityManagerStub());
addInjector(new PackageManagerStub());
addInjector(HCallbackStub.getDefault());
addInjector(new ISmsStub());
addInjector(new ISubStub());
addInjector(new DropBoxManagerStub());
addInjector(new NotificationManagerStub());
addInjector(new LocationManagerStub());
addInjector(new WindowManagerStub());
addInjector(new ClipBoardStub());
addInjector(new MountServiceStub());
addInjector(new BackupManagerStub());
addInjector(new TelephonyStub());
addInjector(new TelephonyRegistryStub());
addInjector(new PhoneSubInfoStub());
addInjector(new PowerManagerStub());
addInjector(new AppWidgetManagerStub());
addInjector(new AccountManagerStub());
addInjector(new AudioManagerStub());
addInjector(new SearchManagerStub());
addInjector(new ContentServiceStub());
addInjector(new ConnectivityStub());
if (Build.VERSION.SDK_INT >= JELLY_BEAN_MR2) {
addInjector(new VibratorStub());
addInjector(new WifiManagerStub());
addInjector(new BluetoothStub());
addInjector(new ContextHubServiceStub());
}
if (Build.VERSION.SDK_INT >= JELLY_BEAN_MR1) {
addInjector(new UserManagerStub());
}
if (Build.VERSION.SDK_INT >= JELLY_BEAN_MR1) {
addInjector(new DisplayStub());
}
if (Build.VERSION.SDK_INT >= LOLLIPOP) {
addInjector(new PersistentDataBlockServiceStub());
addInjector(new InputMethodManagerStub());
addInjector(new MmsStub());
addInjector(new SessionManagerStub());
addInjector(new JobServiceStub());
addInjector(new RestrictionStub());
}
if (Build.VERSION.SDK_INT >= KITKAT) {
addInjector(new AlarmManagerStub());
addInjector(new AppOpsManagerStub());
addInjector(new MediaRouterServiceStub());
}
if (Build.VERSION.SDK_INT >= LOLLIPOP_MR1) {
addInjector(new GraphicsStatsStub());
}
if (Build.VERSION.SDK_INT >= M) {
addInjector(new NetworkManagementStub());
}
if (Build.VERSION.SDK_INT >= N) {
addInjector(new WifiScannerStub());
addInjector(new ShortcutServiceStub());
}
}
}
这个注入过程是发生在io.virtualapp.VApp.attachBaseContext中,因此,每次启动一个子进程都会执行到这里,这会区分是isMainProcess(io.virtualapp)或者isServerProcess(io.virtualapp:x)或者isVAppProcess(被安装APP)来进行不同的注入,可以看到,注入最多的还是在被安装APP的进程中。
运行流程
从启动VirtualApp到运行其中的应用,大致流程如下:
启动host应用
我们启动VirtualApp,其Application为io.virtualapp.VApp。在attachBaseContext()方法中会调用到com.lody.virtual.client.core.PatchManager#injectInternal,但此时为Main Process,不进行系统服务的替换。
启动Server Process
host应用会进行一些初始化,其中就包括获取全部已安装应用,这会调用到com.lody.virtual.client.core.VirtualCore#getAllApps。而这一方法最终会访问com.lody.virtual.server.BinderProvider。由AndroidManifest.xml可知,该provider会运行在新进程io.virtualapp:x中,即Server Process。
由于在新进程中启动组件,同样会首先创建该应用的Application,因此也会调用到com.lody.virtual.client.core.PatchManager#injectInternal。此时,会进行相应系统服务(ActivityManager和PackageManager)的代理构造和替换。
启动VApp Process
点击一个已安装应用,此时会通过替换掉的系统服务访问真实的系统服务(主要是ActivityManager),并在新进程中启动组件com.lody.virtual.client.stub.StubActivity.C0。由AndroidManifest.xml可知,该进程具有后缀:p0。
同样的,在该Activity组件启动之前会初始化io.virtualapp.VApp,并在com.lody.virtual.client.core.PatchManager#injectInternal中完成系统服务的代理构造和替换。
启动client应用
此时,真正的client应用尚未启动,进程io.virtualapp:p0仅仅是作为一个placeholder。StubActivity会从Intent中获取到client应用的相关信息,并修改自身ActivityThread的handler。随后调用startActivity启动client应用。
由于之前Server Process和VApp Process都已完成了相关系统服务的替换,这里会完成client应用的bindApplication调用、构造client应用的LoadedApk,并通过反射完成真正的Application和Activity的创建。
最终,client应用便运行在了我们的VApp Process中。
系统服务的代理和替换
VirtualApp之所以能够实现虚拟空间,是因为其对许多系统服务进行了代理和替换。因此,这部分便是整个框架的核心。系统服务运行在system_server中,Android应用调用系统服务,是通过Binder机制进行IPC。因此,应用所持有的是系统服务的BinderProxy,通过对这些BinderProxer构造代理并替换,便实现了对系统服务的代理和替换。
具体地,我们以com.lody.virtual.client.hook.patchs.am.ActivityManagerPatch为例,这个类实现了对ActivityManager服务的代理和替换。
代理的构造
可以看到,这个类的注记中包含了大量类名:1
2
3
4
5
6@Patch({StartActivity.class, StartActivityAsCaller.class,
StartActivityAndWait.class, StartActivityWithConfig.class, StartActivityIntentSender.class,
StartNextMatchingActivity.class, StartVoiceActivity.class,
GetIntentSender.class, RegisterReceiver.class, GetContentProvider.class,
GetContentProviderExternal.class,
...
而这些列出的每一个类,对应于一个方法的hook,例如,com.lody.virtual.client.hook.patchs.am.StartActivity是ActivityManager服务的startActivity方法的hook。这些类均继承自com.lody.virtual.client.hook.base.Hook,包含了方法beforeCall(), call(), afterCall(),这些方法便是hook的具体内容。
ActivityManagerPatch在创建时,会调用到其父类的方法com.lody.virtual.client.hook.base.PatchDelegate#onBindHooks。这里会检查上述注记中列出的hook,并对符合条件的hook调用addHook()方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22...
Class<? extends PatchDelegate> clazz = getClass();
Patch patch = clazz.getAnnotation(Patch.class);
int version = Build.VERSION.SDK_INT;
if (patch != null) {
Class<?>[] hookTypes = patch.value();
for (Class<?> hookType : hookTypes) {
ApiLimit apiLimit = hookType.getAnnotation(ApiLimit.class);
boolean needToAddHook = true;
if (apiLimit != null) {
int apiStart = apiLimit.start();
int apiEnd = apiLimit.end();
boolean highThanStart = apiStart == -1 || version > apiStart;
boolean lowThanEnd = apiEnd == -1 || version < apiEnd;
if (!highThanStart || !lowThanEnd) {
needToAddHook = false;
}
}
if (needToAddHook) {
addHook(hookType);
}
...
而addHook()最终会调用到com.lody.virtual.client.hook.base.HookDelegate#addHook,其实质便是将这个hook添加至映射表internalHookTable中:1
2
3
4
5
6
7
8
9
10
11public Hook addHook(Hook hook) {
if (hook != null && !TextUtils.isEmpty(hook.getName())) {
if (internalHookTable.containsKey(hook.getName())) {
VLog.w(TAG, "The Hook(%s, %s) you added has been in existence.", hook.getName(),
hook.getClass().getName());
return hook;
}
internalHookTable.put(hook.getName(), hook);
}
return hook;
}
internalHookTable维护了所有的hook,以hook的名称(一般就是所hook的方法的名称)作为key。随后,在com.lody.virtual.client.hook.base.HookDelegate.HookHandler的invoke()方法中,查找表 internalHookTable中是否包含将要执行的方法名;如果有,则依次执行对应hook的beforeCall(), call(), afterCall():1
2
3
4
5
6
7
8
9
10
11
12
13private class HookHandler implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Hook hook = getHook(method.getName());
try {
if (hook != null && hook.isEnable()) {
if (hook.beforeCall(mBaseInterface, method, args)) {
Object res = hook.call(mBaseInterface, method, args);
res = hook.afterCall(mBaseInterface, method, args, res);
return res;
}
}
return method.invoke(mBaseInterface, args);
而这里的类HookHandler,就是构造的Java代理的Handler:1
2
3
4
5
6
7public HookDelegate(T baseInterface, Class<?>... proxyInterfaces) {
this.mBaseInterface = baseInterface;
if (baseInterface != null) {
if (proxyInterfaces == null) {
proxyInterfaces = HookUtils.getAllInterface(baseInterface.getClass());
}
mProxyInterface = (T) Proxy.newProxyInstance(baseInterface.getClass().getClassLoader(), proxyInterfaces, new HookHandler());
对于ActivityManagerPatch来说,这里的baseInterface便是原始的BinderProxy: ActivityManagerProxy1
2
3public ActivityManagerPatch() {
super(new HookDelegate<IInterface>(ActivityManagerNative.getDefault.call()));
}
综上,我们根据baseInterface,为其构造了代理mProxyInterface。从而访问mProxyInterface时,便会执行HookHandler的invoke()方法,进而查找internalHookTable,对设置了hook的方法执行hook。
系统服务的替换
如之前所说,对系统服务的替换,是通过对应用所持有的系统服务的BinderProxy进行替换的。以上是构造代理的基本过程,那么如何将应用所持有的BinderProxy替换成我们构造的代理呢?回到ActivityManagerPatch,这个类的inject()方法完成了实际的替换工作:1
2
3
4
5
6
7
8
9
10@Override
public void inject() throws Throwable {
if (ActivityManagerNative.gDefault.type() == IActivityManager.TYPE) {
ActivityManagerNative.gDefault.set(getHookDelegate().getProxyInterface());
} else if (ActivityManagerNative.gDefault.type() == Singleton.TYPE) {
Object gDefault = ActivityManagerNative.gDefault.get();
Singleton.mInstance.set(gDefault, getHookDelegate().getProxyInterface());
}
...
ActivityManagerNative.gDefault便是应用所持有的原始ActivityManagerProxy对象,通过Java反射,将替换成为getHookDelegate().getProxyInterface()。而替换的内容,便是我们所构造的代理mProxyInterface。
由此,我们完成了对系统服务进行代理和替换的整个过程。随后,在调用系统服务时,便会执行以下操作:
- 访问BinderProxy的代理,即我们设置了hook的代理
- 根据hook的具体内容操作,对数据进行处理;需要调用原始系统服务时,访问原始的BinderProxy
- 真正的系统服务接收到Binder,进行处理并返回
总结
通过以上介绍可以看到,VirtualApp在原有系统服务之上构造了代理,进而为其中的应用搭建了一套虚拟环境,应用可以无感知地运行在这其中。更进一步,我们可以设置这套虚拟环境,使其实现应用多开、非侵入式应用hook等高级功能。
参考资料
https://github.com/asLody/VirtualApp
http://rk700.github.io/2017/03/15/virtualapp-basic/
https://blog.csdn.net/weixin_40581980/article/details/81169266