使用okhttp实现https请求,首先要搞清楚https的请求需要什么,即一份ca证书。 购买的证书,格式为.pfx,带有公钥和私钥,附带一个密码。还有一种格式为.cer的证书,这种证书是没有私钥的。
服务器会将证书配置到tomcat中,客户端则存放在本地,app启动的时候加载进去。
本案例将ca证书放在本地,这里使用.pfx格式的证书
单向验证
有两种写法,先展示一种接近okhttp官方写法的方法:
private void setCertificates(Context context) {
try {
//将ca证书导入输入流
InputStream inputStream = context.getResources().openRawResource(R.raw.aaa);
//keystore添加证书内容和密码
KeyStore keyStore = KeyStore.getInstance(KeyStore.getDefaultType());
keyStore.load(inputStream, CLIENT_KET_PASSWORD.toCharArray());
//证书工厂类,生成证书
CertificateFactory certificateFactory = CertificateFactory.getInstance("X.509");
//生成证书,添加别名
keyStore.setCertificateEntry("test1", certificateFactory.generateCertificate(inputStream));
//信任管理器工厂
TrustManagerFactory trustManagerFactory = TrustManagerFactory.getInstance(TrustManagerFactory.getDefaultAlgorithm());
trustManagerFactory.init(keyStore);
//构建一个ssl上下文,加入ca证书格式,与后台保持一致
SSLContext sslContext = SSLContext.getInstance("TLS");
//参数,添加受信任证书和生成随机数
sslContext.init(null, trustManagerFactory.getTrustManagers(), new SecureRandom());
//获得scoket工厂
SSLSocketFactory sslSocketFactory = sslContext.getSocketFactory();
mOkHttpClient.sslSocketFactory(sslSocketFactory);
//设置ip授权认证:如果已经安装该证书,可以不设置,否则需要设置
mOkHttpClient.hostnameVerifier(new HostnameVerifier() {
@Override
public boolean verify(String hostname, SSLSession session) {
return true;
}
});
inputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
第二种写法,同样有效:
private void setCertificates(Context context) {
try {
//将ca证书导入输入流
InputStream inputStream = context.getResources().openRawResource(R.raw.aaa);
//keystore添加证书内容和密码
KeyStore keyStore = KeyStore.getInstance(KeyStore.getDefaultType());
keyStore.load(inputStream, CLIENT_KET_PASSWORD.toCharArray())
//key管理器工厂
KeyManagerFactory keyManagerFactory = KeyManagerFactory.getInstance(KeyManagerFactory.getDefaultAlgorithm());
keyManagerFactory.init(keyStore, CLIENT_KET_PASSWORD.toCharArray());
//构建一个ssl上下文,加入ca证书格式,与后台保持一致
SSLContext sslContext = SSLContext.getInstance("TLS");
//参数,添加受信任证书和生成随机数
sslContext.init(keyManagerFactory.getKeyManagers(), null, new SecureRandom());
//获得scoket工厂
SSLSocketFactory sslSocketFactory = sslContext.getSocketFactory();
mOkHttpClient.sslSocketFactory(sslSocketFactory);
//设置ip授权认证:如果已经安装该证书,可以不设置,否则需要设置
mOkHttpClient.hostnameVerifier(new HostnameVerifier() {
@Override
public boolean verify(String hostname, SSLSession session) {
return true;
}
});
inputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
值得注意的是,keystore的格式,keystore拓展名对应格式:
JKS:.jks/.ks
JCEKS:.jce
PKCS12:.p12/.pfx
BKS:.bks
UBER:.ubr
所以,如果ca证书用的是.pfx,那么可以这样写:
KeyStore keyStore = KeyStore.getInstance("PKCS12");
如果是.cer的话那么,就用:
KeyStore keyStore = KeyStore.getInstance(KeyStore.getDefaultType());
双向验证
双向验证的前提是,你的app同样生成一个jks的密钥文件,服务器那边会同时有个“cer文件”与之对应。
注意: Java平台默认识别jks格式的证书文件,但是android平台只识别bks格式的证书文件,所以这里还需要将jks的文件转成bks
通过jks文件生成对应的cer文件:
keytool -export -alias test1.jks -file test2.cer -keystore test1.jks -storepass 123456
如果服务端报错keystore文件格式不正确,则我们再将cer文件转换成jks文件:
keytool -import -alias test2.cer -file test2.cer -keystore test3.jks
客户端代码如下:
private void setCertificates(Context context) {
try {
//将ca证书导入输入流
InputStream inputStream = context.getResources().openRawResource(R.raw.aaa);
//keystore添加证书内容和密码
KeyStore keyStore = KeyStore.getInstance(KeyStore.getDefaultType());
keyStore.load(inputStream, CLIENT_KET_PASSWORD.toCharArray());
//证书工厂类,生成证书
CertificateFactory certificateFactory = CertificateFactory.getInstance("X.509");
//生成证书,添加别名
keyStore.setCertificateEntry("test1", certificateFactory.generateCertificate(inputStream));
//信任管理器工厂
TrustManagerFactory trustManagerFactory = TrustManagerFactory.getInstance(TrustManagerFactory.getDefaultAlgorithm());
trustManagerFactory.init(keyStore);
//双向验证,配置服务器验证客户端的证书
InputStream inputStream1 = context.getResources().openRawResource(R.raw.bbb);
KeyStore keyStore1 = KeyStore.getInstance(KeyStore.getDefaultType());
keyStore1.load(inputStream1, CLIENT_KET_PASSWORD_1.toCharArray());
KeyManagerFactory keyManagerFactory = KeyManagerFactory.getInstance(KeyManagerFactory.getDefaultAlgorithm());
keyManagerFactory.init(keyStore1, CLIENT_KET_PASSWORD_1.toCharArray());
//构建一个ssl上下文,加入ca证书格式,与后台保持一致
SSLContext sslContext = SSLContext.getInstance("TLS");
//参数,添加受信任证书和生成随机数
sslContext.init(keyManagerFactory.getKeyManagers(), trustManagerFactory.getTrustManagers(), new SecureRandom());
//获得scoket工厂
SSLSocketFactory sslSocketFactory = sslContext.getSocketFactory();
mOkHttpClient.sslSocketFactory(sslSocketFactory);
//设置ip授权认证:如果已经安装该证书,可以不设置,否则需要设置
mOkHttpClient.hostnameVerifier(new HostnameVerifier() {
@Override
public boolean verify(String hostname, SSLSession session) {
return true;
}
});
inputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
中间人劫持攻击
https也不是绝对安全的,如下图所示为中间人劫持攻击,中间人可以获取到客户端与服务器之间所有的通信内容: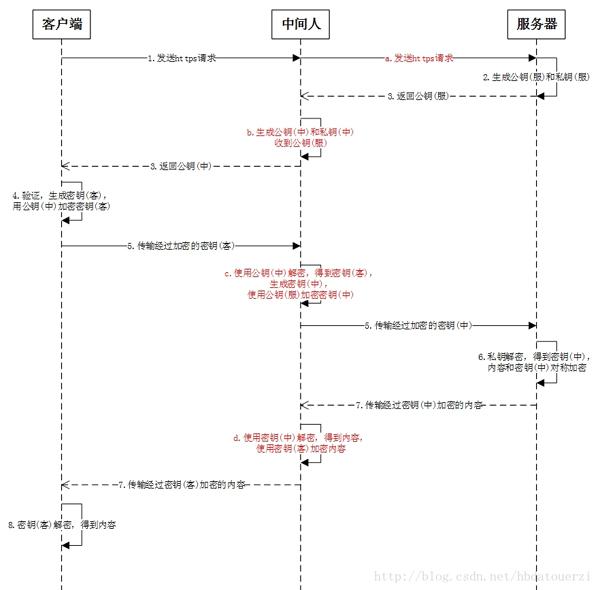
中间人截取客户端发送给服务器的请求,然后伪装成客户端与服务器进行通信;将服务器返回给客户端的内容发送给客户端,伪装成服务器与客户端进行通信。
通过这样的手段,便可以获取客户端和服务器之间通信的所有内容。
使用中间人攻击手段,必须要让客户端信任中间人的证书,如果客户端不信任,则这种攻击手段也无法发挥作用。
造成中间人劫持的原因是:没有对服务端证书及域名做校验或者校验不完整。下面是错误的写法: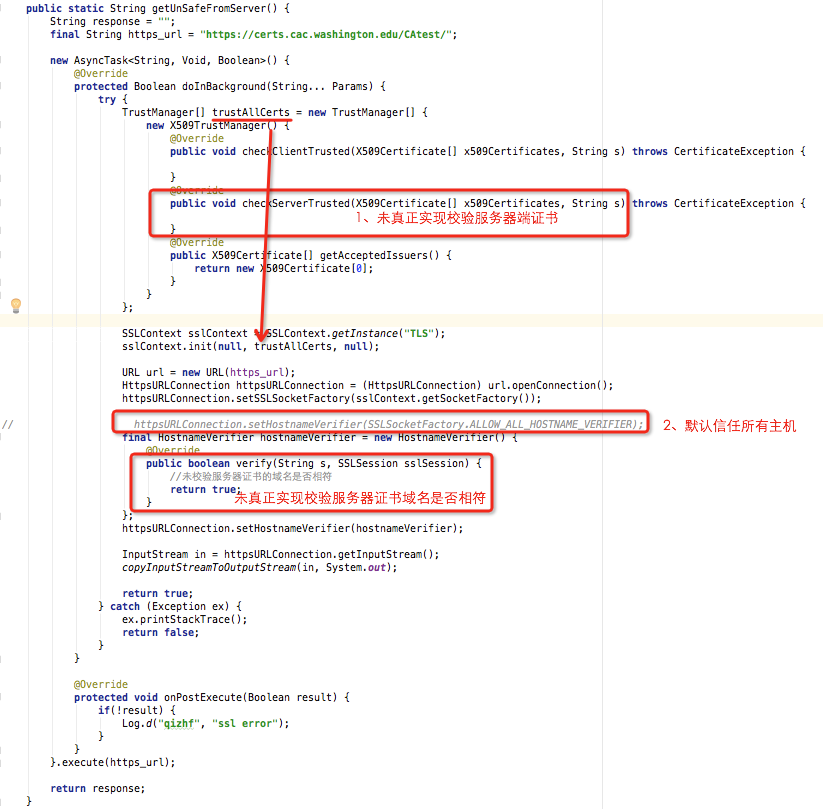
正确的写法是真正实现TrustManger的checkServerTrusted(),对服务器证书域名进行强校验或者真正实现HostnameVerifier的verify()方法。
真正实现TrustManger的checkServerTrusted()代码如下: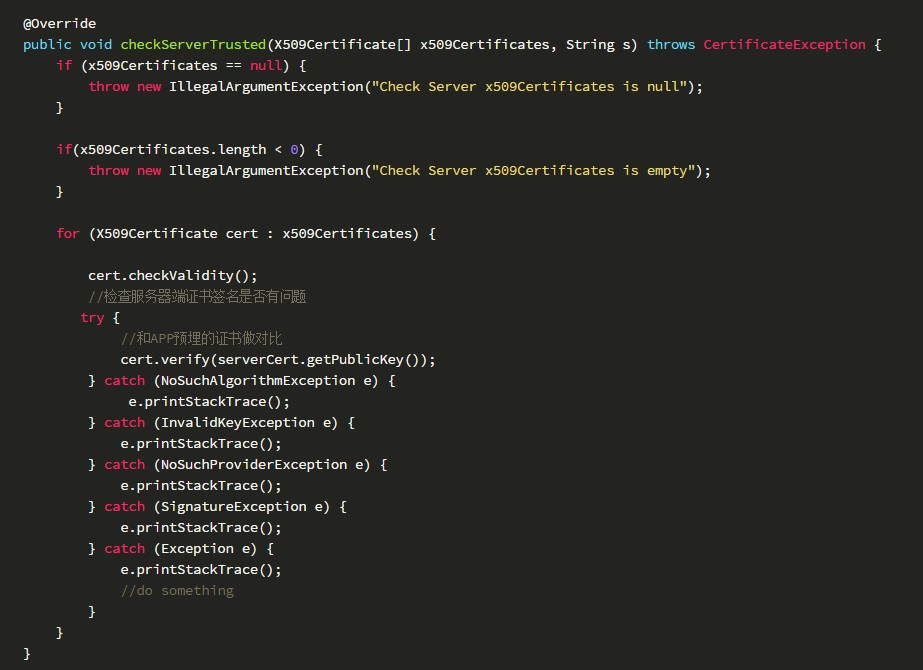
其中serverCert是APP中预埋的服务器端公钥证书
对服务器证书域名进行强校验:
真正实现HostnameVerifier的verify()方法: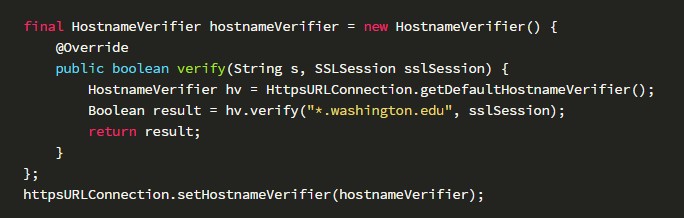
另外一种写法证书锁定,直接用预埋的证书来生成TrustManger,过程如上面介绍okhttp使用https方式